

As AI adoption continues to accelerate across industries, the demand for high-performance GPU infrastructure has grown significantly. From startups building generative AI platforms to enterprises training large-scale machine learning models, organizations now require scalable computing environments that can handle modern AI workloads efficiently.
Among the most trusted enterprise cloud GPU available today, the NVIDIA A100 remains one of the preferred choices for AI training, inference, deep learning, and high-performance computing environments.
If you are evaluating the latest NVIDIA A100 price in India, this guide will help you understand the following:
- deployment pricing
- cloud infrastructure options
- enterprise GPU environments
- dedicated server considerations
- workload suitability
- scalability requirements
Whether you are deploying AI applications, training machine learning models, or scaling enterprise infrastructure, understanding the capabilities and pricing structure of NVIDIA environments is essential before making an infrastructure decision.
What is NVIDIA A100?
The NVIDIA A100 is an enterprise-grade GPU built on NVIDIA’s Ampere architecture and designed specifically for advanced AI and high-performance computing workloads.
Unlike consumer-grade GPUs, it is engineered for enterprise environments where:
- scalability
- memory bandwidth
- continuous performance
- multi-GPU deployment
- infrastructure reliability
play a critical role.
The GPU is widely used for:
- AI model training
- large language models
- deep learning
- inference pipelines
- NLP workloads
- recommendation engines
- scientific computing
- generative AI applications
Even in 2026, it continues to power production AI environments globally because it offers a strong balance between performance, stability, and infrastructure efficiency.
NVIDIA A100 Price in India (2026)
The NVIDIA A100 price in India depends on several infrastructure and deployment factors, including:
- GPU configuration
- deployment scale
- cloud or dedicated infrastructure
- storage requirements
- networking capabilities
- workload intensity
Organizations can choose between the following:
- cloud-based GPU deployments
or - dedicated enterprise GPU servers.
Businesses planning advanced AI deployments often compare NVIDIA A100 infrastructure with newer GPUs to evaluate performance and budget requirements. The NVIDIA H100 price is generally higher because it is designed for large-scale AI training, advanced LLM workloads, and enterprise-grade generative AI environments. Organizations working on high-performance AI applications often evaluate both GPUs before selecting the right infrastructure for long-term scalability.
Estimated NVIDIA A100 Pricing
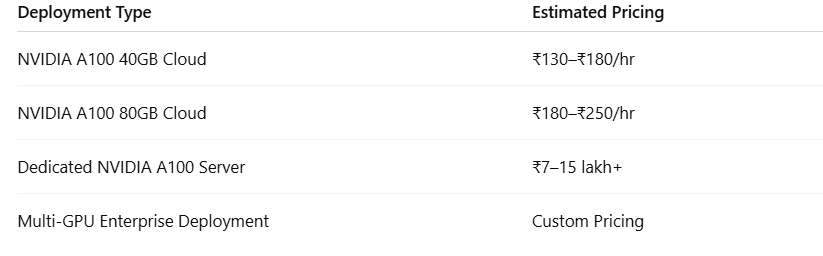
For many businesses, cloud-based GPU infrastructure provides a more flexible and cost-effective deployment model compared to maintaining physical GPU hardware internally.
Why Businesses Choose NVIDIA A100 Infrastructure
Organizations deploying AI applications require infrastructure that can scale efficiently while maintaining consistent performance.
It remains widely adopted because it supports:
- enterprise AI training
- scalable inference workloads
- generative AI applications
- production machine learning environments
- high-performance computing workloads
Businesses also prefer NVIDIA infrastructure because it allows the following:
- flexible resource allocation
- rapid deployment
- enterprise scalability
- lower operational complexity
- optimized AI performance
This makes it particularly valuable for:
- AI startups
- SaaS platforms
- research organizations
- enterprise AI teams
- machine learning environments
NVIDIA A100 40GB vs 80GB
One of the key differences between NVIDIA A100 deployments comes down to memory capacity and workload requirements.

The 80GB configuration is typically preferred for:
- large language models
- memory-intensive AI workloads
- transformer-based environments
- enterprise inference pipelines
The 40GB deployment remains a practical option for organizations looking to balance AI performance with infrastructure cost.
The pricing of GPU infrastructure depends on several factors, including GPU configuration, deployment type, cloud resources, storage requirements, and workload scale. Enterprise GPU pricing may vary between dedicated infrastructure and cloud-based deployments, especially for AI training, inference, and high-performance computing environments. Businesses usually compare GPU performance, scalability, and operational costs before choosing the right AI infrastructure solution.
NVIDIA A100 for Enterprise AI Environments
Modern AI workloads demand infrastructure capable of handling:
- large datasets
- parallel processing
- continuous model training
- scalable inference
- distributed computing
The NVIDIA is widely deployed across enterprise AI environments because it delivers:
- high memory bandwidth
- optimized tensor performance
- multi-instance GPU capabilities
- enterprise reliability
- scalable infrastructure support
These capabilities make the GPU suitable for both research-driven AI environments and production-scale enterprise deployments.
Cloud vs Dedicated NVIDIA A100 Deployment
Organizations planning GPU infrastructure deployments often compare the following:
- dedicated GPU ownership and
- cloud-based deployment models.
Dedicated NVIDIA A100 Infrastructure
Dedicated GPU environments are commonly used for:
- long-term AI workloads
- enterprise AI platforms
- continuous GPU utilization
- private infrastructure deployments
However, dedicated deployments also require:
- hardware investment
- cooling systems
- networking infrastructure
- maintenance management
- operational oversight
Cloud-Based NVIDIA A100 Deployment
Cloud infrastructure offers greater flexibility for organizations that require the following:
- rapid scalability
- flexible resource allocation
- lower upfront investment
- temporary AI environments
- workload-based billing
Cloud deployments also simplify infrastructure management, allowing teams to focus more on AI development and less on hardware operations.
For many growing AI teams, cloud infrastructure provides a more efficient and scalable deployment model.
Why NVIDIA A100 Still Matters in 2026
While newer AI accelerators continue entering the market, the NVIDIA A100 remains one of the most widely deployed enterprise GPUs globally.
The reason is simple:
The NVIDIA A100 delivers a strong balance between
- performance
- infrastructure efficiency
- deployment flexibility
- operational scalability
- enterprise reliability
For many organizations, the GPU continues to provide the level of performance needed for AI workloads without requiring the significantly higher infrastructure investment associated with newer architectures.
This makes the NVIDIA a practical and reliable option for:
- enterprise AI platforms
- production inference systems
- scalable AI environments
- machine learning deployments
- GPU cloud infrastructure
How to Choose the Right NVIDIA A100 Provider
Before selecting enterprise GPU infrastructure, businesses should evaluate:
- deployment flexibility
- pricing transparency
- GPU availability
- infrastructure reliability
- network performance
- storage scalability
- technical support
- enterprise deployment capabilities
A reliable infrastructure provider should offer the following:
- scalable GPU environments
- enterprise networking
- rapid deployment
- flexible resource allocation
- consistent uptime
- secure infrastructure management
These factors become increasingly important when deploying AI workloads at scale.
Final Thoughts
The NVIDIA A100 continues to remain one of the most trusted enterprise GPUs for AI training, deep learning, inference, and scalable computing environments in 2026.
Whether you are building AI applications, deploying machine learning infrastructure, or scaling enterprise workloads, understanding NVIDIA infrastructure and deployment pricing is essential before making long-term decisions.
For many organizations, cloud-based NVIDIA environments provide the flexibility, scalability, and infrastructure efficiency needed to support modern AI workloads without the operational complexity of maintaining dedicated GPU hardware internally.
Frequently Asked Questions
1. What is the NVIDIA A100 price in India?
The NVIDIA A100 price in India depends on deployment type, GPU configuration, infrastructure requirements, and workload scale. Pricing may vary between cloud deployments and dedicated enterprise environments.
2. Is NVIDIA A100 suitable for AI training?
Yes, the NVIDIA A100 is designed specifically for AI training, deep learning, inference, and enterprise GPU workloads that require scalable high-performance infrastructure.
3. Is cloud deployment suitable for NVIDIA A100 environments?
Cloud-based NVIDIA A100 deployments provide flexibility, scalable resource allocation, and lower infrastructure investment, making them suitable for many AI teams and enterprise environments.
4. Why is NVIDIA A100 widely used in enterprise AI?
The NVIDIA A100 is widely adopted because it offers enterprise-grade performance, scalable infrastructure support, optimized AI acceleration, and reliable deployment capabilities for modern AI workloads.

