

Performance Upgrade
Enhance work with streamlined computing and networking. We do this by making our cloud GPU architecture faster, with less latency and a smooth run time of AI and ML workloads.
Enterprise-grade NVIDIA GPU powered cloud servers for AI, ML and HPC workloads with predictable pricing in India.
Trusted Globally









Inhosted.ai provides enterprise-grade cloud GPU infrastructure in India using NVIDIA GPU servers for AI, deep learning, and high-performance computing workloads.
Performance Upgrade
Enhance work with streamlined computing and networking. We do this by making our cloud GPU architecture faster, with less latency and a smooth run time of AI and ML workloads.

Infinite Flexibility and scalability.
Scaling You can scale with one of the best cloud server hosting providers that are in the market today. Since we are startups and businesses, we expand with your business at ease.

Predictable Cloud Cost
Get transparent costs with our flexible pricing scheme- Inhosted.ai is one of the most predictable providers of cloud server India, in terms of budgeting and ROI.
Inhosted.ai offers GPU dedicated server hosting in India that provides exclusive access to NVIDIA GPUs, CPU, and memory for AI training, inference, and data-intensive workloads.
Elastic GPU Power
Pay-as-you-train. Scale seamlessly.
Global AI Backbone
Low-latency GPU clusters worldwide.
Enterprise Reliability
99.95% SLA-backed availability.
Enterprise-grade GPU infrastructure trusted by AI-driven organizations across the globe. Built for scale, speed, and security.
Deploy GPUs Instantly
Launch high-performance A100 and H100 clusters in seconds. No queues. No quotas. Pure compute power.
Compliant. Certified. Secure.
Infrastructure aligned with ISO 27001, ISO 27017 & ISO 27018 for mission-critical workloads.
Data That Moves as Fast as Your Model
Predictable throughput under high-speed workloads with GPU-optimized networking.
Seamless Scalability
Scale from a single instance to thousands of GPUs with or without distributed clusters.
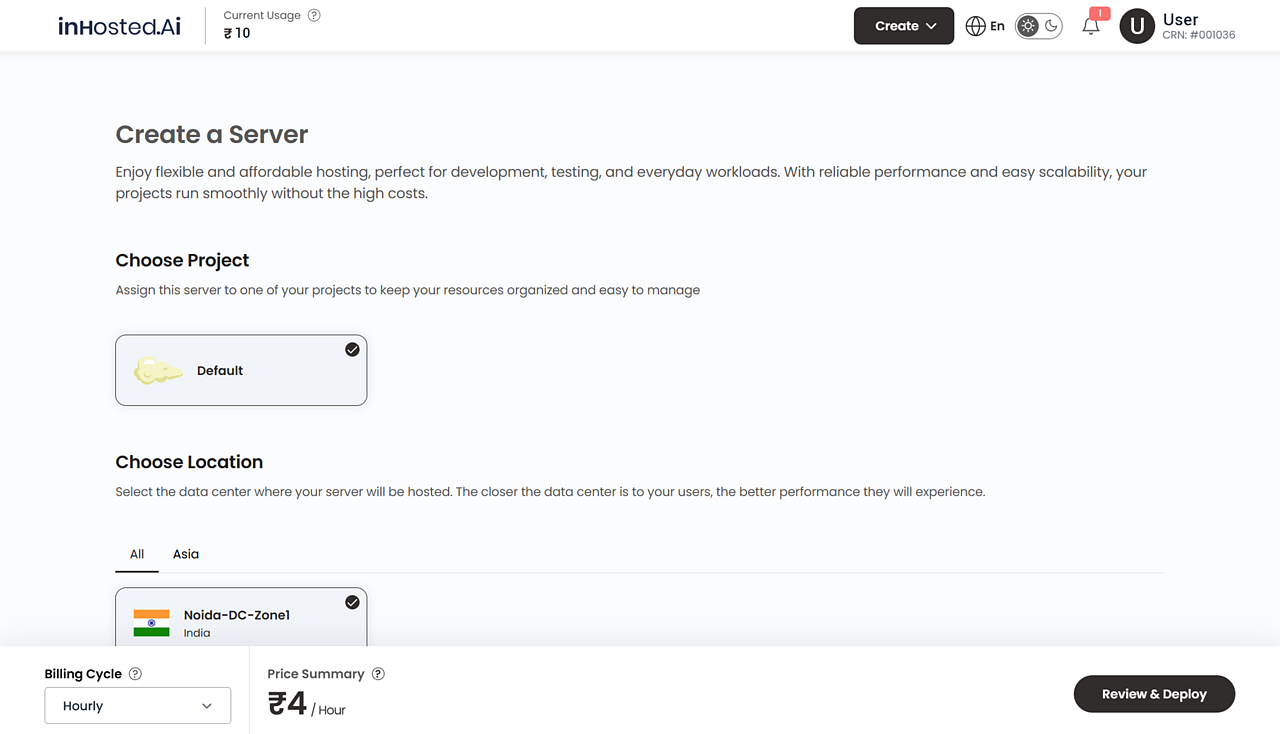
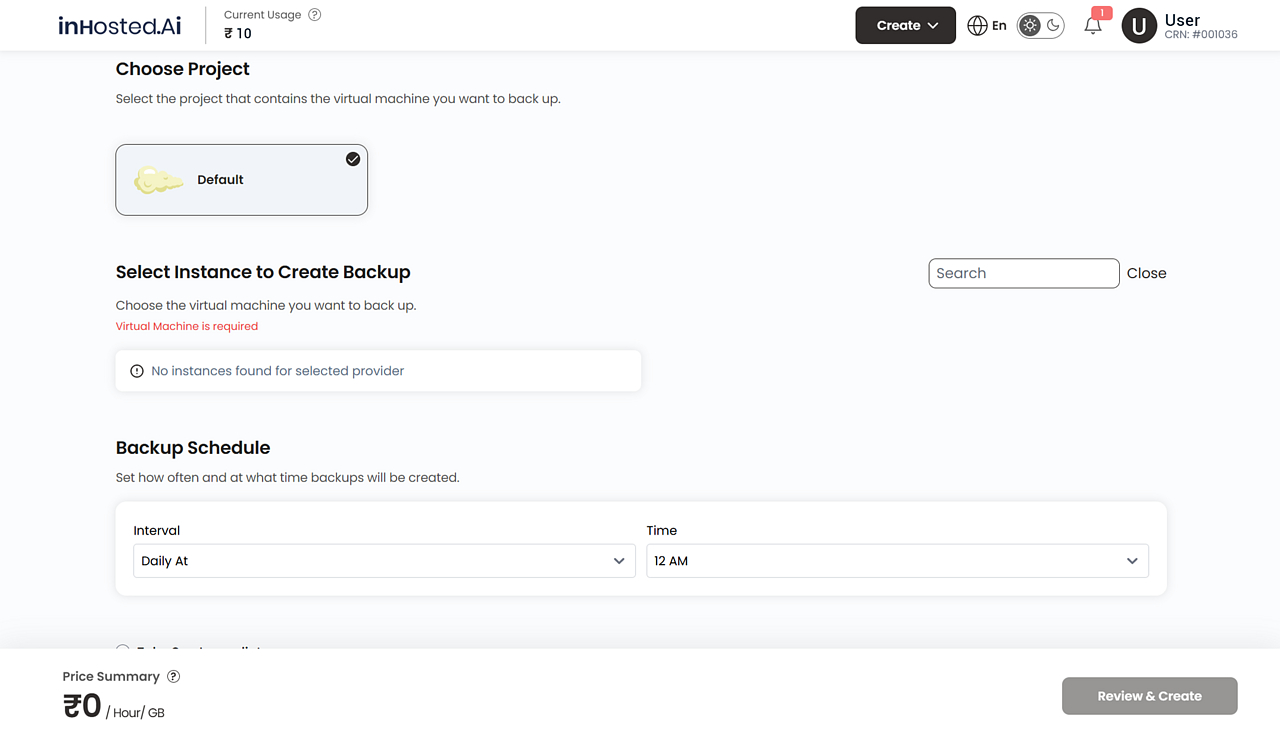
Start your cloud server within a few seconds. Select operating system, compute, storage, and networking arrangements - in a single stream.
Protect data and ensure a timely backup and fast recovery. Your workloads are safe and robust and they are constantly available.
Our professionals will offer 24/7 support to maintain high availability and performance of your cloud server infrastructure.

Inhosted.ai is a platform that enables AI development teams to create systems on the next generation. You can use our platform to get unmatched performance and reliability whether you are training models with NVIDIA AI GPU, trying out deep learning, or putting more serious production workloads to the test.
High-performance cloud infrastructure built for AI, HPC, and global workloads.
One of the best cloud server platforms for AI and HPC
High-performance GPU dedicated server options
Advanced server virtualization in cloud computing
Trusted cloud server India provider
Reliable GPU cloud providers for global workloads
From startups to large enterprises, organizations across India rely on Inhosted.ai for secure, scalable, and high-performance cloud server and GPU cloud infrastructure.
Join Our GPU Cloud
inhosted.ai helped us move GPU workloads in seconds. Uptime has been rock-solid and performance consistent across regions — exactly what we needed for live inference.
Best experience we’ve had with GPU cloud. Instant spin-ups, clear billing, and quick support. Our vision models deploy faster and stay within budget.
We run multi-region inference and scheduled retraining on inhosted.ai. Scaling from 10 to 400+ GPUs takes minutes, networking is consistent, and storage hits the throughput we need.
Training times dropped and costs stayed predictable. The support team was proactive throughout deployment.
Migrating our LLM training stack to inhosted.ai gave us a 3× throughput boost. H100 clusters came online in seconds and billing stayed predictable. We cut project timelines by weeks.
Predictable pricing, high GPU availability, and fast storage — we ship models faster with fewer surprises.
The L40S cluster gives us everything — speed, efficiency, and visual quality. Our AI-powered product rendering now completes 4× faster, and uptime stays rock solid.
We run GenAI and computer-vision pipelines on inhosted.ai. Storage throughput keeps GPUs fed, and orchestration is simple. Most dependable stack we’ve used.
Migrating our LLM training stack to inhosted.ai gave us a 3× throughput boost. H100 clusters came online in seconds and billing stayed predictable. We cut project timelines by weeks.
Predictable pricing, high GPU availability, and fast storage — we ship models faster with fewer surprises.
The L40S cluster gives us everything — speed, efficiency, and visual quality. Our AI-powered product rendering now completes 4× faster, and uptime stays rock solid.
We run GenAI and computer-vision pipelines on inhosted.ai. Storage throughput keeps GPUs fed, and orchestration is simple. Most dependable stack we’ve used.
inhosted.ai helped us move GPU workloads in seconds. Uptime has been rock-solid and performance consistent across regions — exactly what we needed for live inference.
Best experience we’ve had with GPU cloud. Instant spin-ups, clear billing, and quick support. Our vision models deploy faster and stay within budget.
We run multi-region inference and scheduled retraining on inhosted.ai. Scaling from 10 to 400+ GPUs takes minutes, networking is consistent, and storage hits the throughput we need.
Training times dropped and costs stayed predictable. The support team was proactive throughout deployment.
A GPU cloud refers to a cloud computing system which offers access to the high-performance GPU servers to use in activities such as AI training, deep learning, and data processing. It enables users to execute workloads, which are powered by high-performance workloads without the need to acquire physical hardware.
A cloud GPU is available in the form of a cloud server - simply choose a gamified instance. Upon the launch, you are able to deploy applications or train models or process huge amounts of data with high-performance computer resources.
The most affordable cloud GPU is based on the needs of use and performance. The cheaper GPU instances are great when developing and testing applications, and the expensive ones would be efficient in big data AI tasks.
GPU (unit) is an abbreviation that is used to denote Graphics Processing Unit. It is created to process parallel computing activities and is commonly applied to AI, machine learning, and high-performance computing systems.
Not always. Most applications can be effectively used with a normal cloud server; however, more complex workloads like AI training or deep learning are greatly improved with the use of a GPU cloud.
Cloud server is a virtual computer server that is deployed in a cloud system that supplies computing resources like computing power, storage, and networking on demand and scale.
Examples Virtual Machines Virtual machines can be used as web hosts, data processing, AI loads, as well as to create a dedicated set of compute nodes on a single graphics card.
There are four major forms of cloud computing:
1. Public Cloud - It is an infrastructure shared by cloud providers.
2. Private Cloud - Single organization dedicated environment.
3. Hybrid Cloud - Public and private cloud.
4. Multi-Cloud - Engaging the use of more than one cloud provider to provide
flexibility.
